

“Network error: There’s a problem connecting to the application.”
Other than the dreaded “blue screen of death,” a network error warning is quite possibly a hard-working employee’s most aggravating computer message—especially because it always seems to happen at the absolute worst moment, like some kind of cruel joke. Maybe it’s also because in our fast-paced, always-available world, every moment feels urgent. And if we’re going to make ourselves available at all times, we expect no less from our apps—whether for business or leisure.
For cloud-based business communications and collaboration solutions, the importance of continuous availability only increases. Because communication is at the heart of any successful organisation, communications solutions need to withstand a multitude of obstacles. These include natural disasters, seasonal surges (such as the first day of school or holiday buying), unexpected surges (such as what we’ve experienced with COVID-19), or company-specific issues (such as hosting a large all-hands session online). In addition to these variables, Unified Communications as a Service (UCaaS) and Contact centre as a Service (CCaaS) providers also need to remain available across many different devices (laptop, mobile, or tablet) and connectivity options (WiFi, 3G/4G/5G, or a switch from one to the other) that customers might use to connect.
What does “Five 9s” mean (also known as “Five Nines”)?
The availability of a cloud solution is usually expressed as a percentage of the amount of time that solution is up and running (known as uptime) in a given year. Most enterprise communications solution providers offer Service Level Agreements (SLAs) that commit to a certain minimum percentage of uptime in a given period (or conversely maximum downtime).
In the figure below, you can see how availability percentages equate to downtime over the course of days, weeks, months, and years. In a perfect world, a cloud solution would be available 100% of the time. Unfortunately, we don’t live in a perfect world, but the good news is that when it comes to uptime, we’re not far off. For example, some companies offer 99.999% availability (also known as “Five 9s”), which translates to 5.26 minutes of downtime for that app per year. Of course, not every company can guarantee that level of uptime, and lower guarantees can translate to possibly significant downtime. For example, 95% availability—which sounds like a high number—actually equates to up to 18 days of downtime annually.
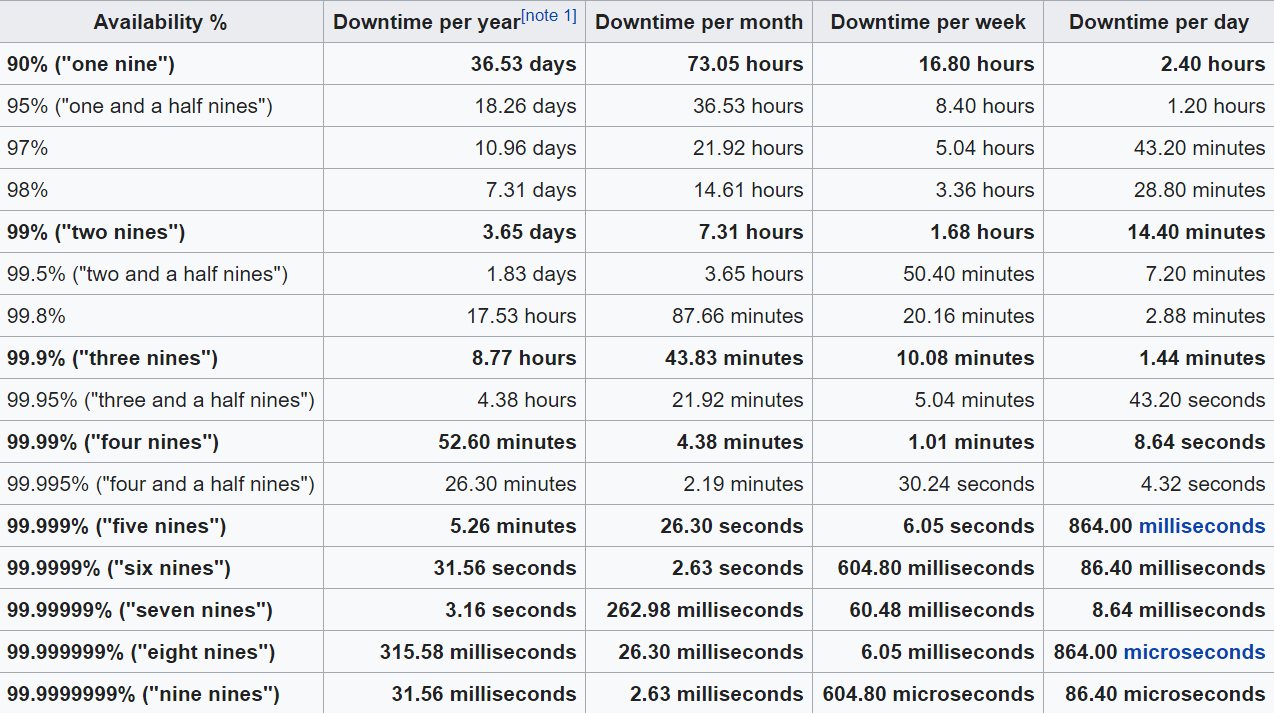
Service Level Agreements guarantee the availability of cloud applications. Lower guarantees can lead to more downtime.
Increased downtime for cloud communications apps can actually have potentially devastating consequences, particularly in certain industries. For example:
- Healthcare: Patients can’t reach doctors for critical information
- Education: Teachers can’t teach remotely
- Public sector: Citizens can’t reach critical government services
- Sales: Sales teams don’t have access to the tools to close deals
- Support: Customer requests go unanswered and customer satisfaction suffers
How cloud providers ensure high availability
There are some critical elements that all highly available Software as a Service (SaaS) companies need to get right, starting with building a scalable, redundant, and secure infrastructure. Here are a few of the hallmarks of highly available solutions:
- It’s critical to host cloud solutions in top tier data centres with geographic redundancy, meaning in the event of an outage in one data centre, another data centre in another location is already set up to automatically handle the load with no issues.
- Providers must also ensure this kind of capability within each data centre by using similar architectures that feature multiple layers of redundancy in case problems arise.
- Maintaining high levels of uptime requires providers who build advanced system monitoring capabilities that allow them to identify issues before they happen and quickly resolve and remediate them when they do.
- Highly available solutions providers have strong internal controls and policies in place to minimise risk and ensure uptime.
How RingCentral builds Five 9s availability
RingCentral’s cloud architecture is built on what’s known as a multi-cloud, multi-network, point-of-delivery (PoD) design. In other words, it uses a modular approach that allows it to intelligently scale and manage increases in usage across messaging, video meetings, and phone solutions, while also providing resiliency and redundancy. The multi-tenant network is designed with built-in 2x capacity, which means customers can double their usage overnight without an issue. Also, systems are designed with concurrent usage in mind. This ensures that the service is always available even when there are usage fluctuations at the customer’s end.
RingCentral maintains “geo-redundant data centres,” which means they’re similarly configured across multiple regions to ensure that service continues despite possible outages. In the event of a data centre failure, RingCentral’s automated systems (built with active-active design), in conjunction with an always-on and world-class network operations centre (NOC), ensure a rapid transition to back-up systems as needed to maintain uninterrupted service availability. Simply put, should an issue arise in any one data centre, another data centre automatically assumes the load with no downtime.
RingCentral employs three layers of network and service redundancy to ensure that customers’ phone systems remain up and running:
- Our data centres provide the first layer of redundancy. Data between bi-coastal locations is synchronised consistently, with latency of less than one minute. Each component has a redundant power supply, which delivers seamless operation and 99.999% availability in case of geographic outages or any natural disaster. In fact, RingCentral has delivered eight consecutive quarters of 99.999% uptime SLA for our flagship product RingCentral Office. The data centres share hosted facilities space with some of the world’s largest Internet companies and financial institutions. In addition, they’re in close physical proximity to the world’s top 20 Internet exchange points.
- Our architecture is vendor-agnostic and commodity-based, meaning it’s fully replaceable and fault-tolerant, providing a second layer of redundancy.
- Our third layer of redundancy utilises both load balancing and failover technology to keep our systems continuously up and running. For example, primary and secondary servers contain multiple servers that back each other up.
Beyond Five 9s: A commitment to relentless innovation
In addition to the architecture of RingCentral systems, we also continue to make significant investments in research and development for our applications. There have been several areas in particular where RingCentral has concentrated its attention in an effort to continuously improve our availability:
Agile development: With decades of stable, mature operational procedures, our proven architecture enables agile development with the ability to support our growing global customer base and partners.
Application Lifecycle Management: Our investments here help minimise errors, disruptions, and the risk of failure. Our engineering, cloud operations, and support teams work in concert with customers to deploy new innovations while minimising potential impacts. Our PoD deployment architecture, combined with our rigorous testing, Q&A, and staging processes, ensures that changes get synchronised while isolating updates and changes as they’re rolled into production. This very controlled synchronisation of updates means that changes don’t inadvertently create delays, outages, or downtime. It’s also important that we work closely with customers to consider critical situational factors (e.g., surges in usage for the first day of virtual school) and evaluate the most appropriate times for change. It’s critical to ensure that any changes have been made and tested well before these major events.
Sophisticated machine learning (ML) and artificial intelligence (AI) automation: When it comes to insights, collecting data is the easy part. RingCentral has built the supporting technology infrastructure and combined that knowledge with decades of industry expertise in messaging, video, and phone to create meaningful and actionable insights. Our ML and AI layers are built on a single data lake that aggregates all operational, usage, and simulated testing data to identify events, correlate them, respond, and remediate. RingCentral’s sophisticated architecture is the key to enabling a data-driven approach to product development, engineering, operations, and support. RingCentral monitors and manages every aspect of the service from top to bottom—from edge to core—to ensure the highest quality, reliability, and security. This architecture has also enabled RingCentral to provide customers with high quality-of-service analytics and insights in a single pane of glass across messaging, video meetings, and phone with tremendous detail.
Team building and a culture of trust: RingCentral teams prepare for everything using rigorous testing to build tribal knowledge. Everybody brings a different opinion and skillset. Such exercises build trust in each other’s capabilities so teams can rely on one another in every situation.
Questions you should ask your service provider
As we discussed earlier, providers’ SLAs vary, with differing levels of commitment to uptime. When evaluating cloud communication and collaboration solutions, be sure to get detailed responses to the following questions about uptime:
- How is the service provider ensuring data redundancy?
- How is the infrastructure prepared for events and surges your business might experience?
- Does the provider conduct in-depth and frequent disruptive testing ( the process of simulating failures in real-world situations), disaster recovery tests? Are the test results and findings shared with customers?
- What are the provider’s business continuity plans? Be sure to go beyond whether the provider has a business continuity plan to determine how often they test and revise it, for example.
- Ask for supporting third-party test reports and accreditations, wherever applicable.
Originally published 01 Sep, 2020, updated 23 Sep, 2020



